大语言模型中的回调函数
为什么要在大语言模型中使用回调函数
Function Calling的使用是为了克服大语言模型的下述缺点
- 回答的一致性。在函数调用之前,LLMs 的回复是非结构化且不一致的。如果我们能够更好地控制响应格式,我们就可以更轻松地将响应下游集成到其他系统。(这一点通过调整 prompt 也可以做到)
- 外部数据。 能够在聊天上下文中使用应用程序其他来源的数据,比如可以让 LLMs 回答诸如“北京现在的天气怎么样的”的问题
架构
LLMs 使用回调函数,本质上是对用户输入 prompt 的自动拆解,利用拆解出来的参数和自动识别出的函数名称,调用外部资源,然后将返回的外部资源添加到用户的 prompt 之中,再次调用 LLMs,从而得到返回结果
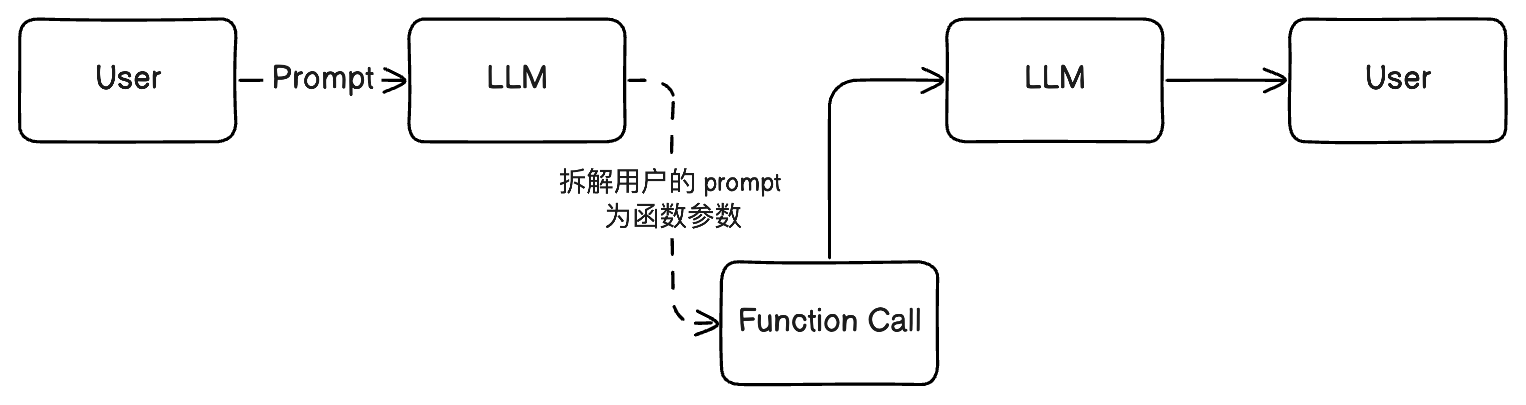
实现
Step1 声明回调函数
# 用户输入
messages= [ {"role": "user", "content": "Find me a good course for a beginner student to learn Azure."} ]
messages= [ {"role": "user", "content": "你好,一个高级工程师想学习 Azure,他已经有 10 年的开发经验,可以用哪些资料做参考"} ]
# 这里你可以定义多个函数
# 这里只是函数的声明,大语言模型会按照这里的定义的 schema 去拆分用户的 prompt,并填充进对应的参数中
functions = [
{
"name":"search_courses",
"description":"Retrieves courses from the search index based on the parameters provided",
"parameters":{
"type":"object",
"properties":{
"role":{
"type":"string",
"description":"The role of the learner (i.e. developer, data scientist, student, etc.)"
},
"product":{
"type":"string",
"description":"The product that the lesson is covering (i.e. Azure, Power BI, etc.)"
},
"level":{
"type":"string",
"description":"The level of experience the learner has prior to taking the course (i.e. beginner, intermediate, advanced)"
}
},
"required":[
"role"
]
}
}
]
response = client.chat.completions.create(model="gpt-3.5-turbo",
messages=messages,
functions=functions,
function_call="auto")
Step2 定义回调函数的具体实现
# 这里是函数的具体实现
def search_courses(role, product, level="beginner"):
url = "https://learn.microsoft.com/api/catalog/"
params = {
"role": role,
"product": product,
"level": level
}
response = requests.get(url, params=params)
modules = response.json()["modules"]
results = []
for module in modules[:5]:
title = module["title"]
url = module["url"]
results.append({"title": title, "url": url})
return str(results)
# Check if the model wants to call a function
if getattr(getattr(response_message, 'function_call', None), 'name', None):
if response_message.function_call.name:
print("Recommended Function call:")
print(response_message.function_call.name)
print()
# Call the function.
function_name = response_message.function_call.name
available_functions = {
"search_courses": search_courses,
}
# 文本和具体函数名称的映射
function_to_call = available_functions[function_name]
function_args = json.loads(response_message.function_call.arguments)
function_response = function_to_call(**function_args)
print("Output of function call:")
print(function_response)
print(type(function_response))
# Add the assistant response and function response to the messages
messages.append( # adding assistant response to messages
{
"role": response_message.role,
"function_call": {
"name": function_name,
"arguments": response_message.function_call.arguments,
},
"content": None
}
)
messages.append( # adding function response to messages
{
"role": "function",
"name": function_name,
"content":function_response,
}
)
print("Messages in next request:")
print(messages)
print()
Step3 再次调用大语言模型,返回标准化的输出
second_response = client.chat.completions.create(
messages=messages,
model="gpt-3.5-turbo",
function_call="auto",
functions=functions,
temperature=0
) # get a new response from GPT where it can see the function response
print(second_response.choices[0].message)
结果示例
对于一个有10年开发经验且级别为高级的学生来说,以下资料可以作为参考:
1. [Advanced PyBryt for Classroom Auto-assessment](https://learn.microsoft.com/en-us/training/modules/advanced-pybryt/?WT.mc_id=api_CatalogApi)
2. [Enrich your data with Azure AI Language](https://learn.microsoft.com/en-us/training/modules/enrich-search-index-using-language-studio/?WT.mc_id=api_CatalogApi)
3. [Implement Azure App Service on Kubernetes with Arc](https://learn.microsoft.com/en-us/training/modules/configure-application-kubernetes-arc/?WT.mc_id=api_CatalogApi)
4. [Implement Datacenter Firewall and Software Load Balancer on Azure Stack HCI](https://learn.microsoft.com/en-us/training/modules/implement-firewall-load-balancer/?WT.mc_id=api_CatalogApi)
这些资料将帮助学生深入学习 Azure 相关的知识。
其他
微软提供的 Learn API 还是挺不错的,作为 GET 接口的测试可以以备不时之需
该 API 是基于 REST 的 Web API,返回 JSON 编码的响应。 若要请求完整目录,请将 GET 请求发送到:https://learn.microsoft.com/api/catalog/,限制的参数格式:{“level”: “advanced”,“product”: “Azure”,“role”: “student”}
.