Spark 入门
从 Hadoop 开始
Apache Hadoop 是一个框架,允许跨计算机集群对大型数据集进行分布式处理。Hadoop 的出现打破了单个服务器的限制,服务器从一台扩展到成千上万台。Hadoop 有 3 个核心组件:
- Hadoop Distributed File System(HDFS): 一种分布式存储文件系统,提供对应用程序数据的高吞吐量访问。
- Yet Another Resource Negotiator (YARN): 作业调度和集群资源管理框架。
- MapReduce :用于并行处理大型数据集的系统。
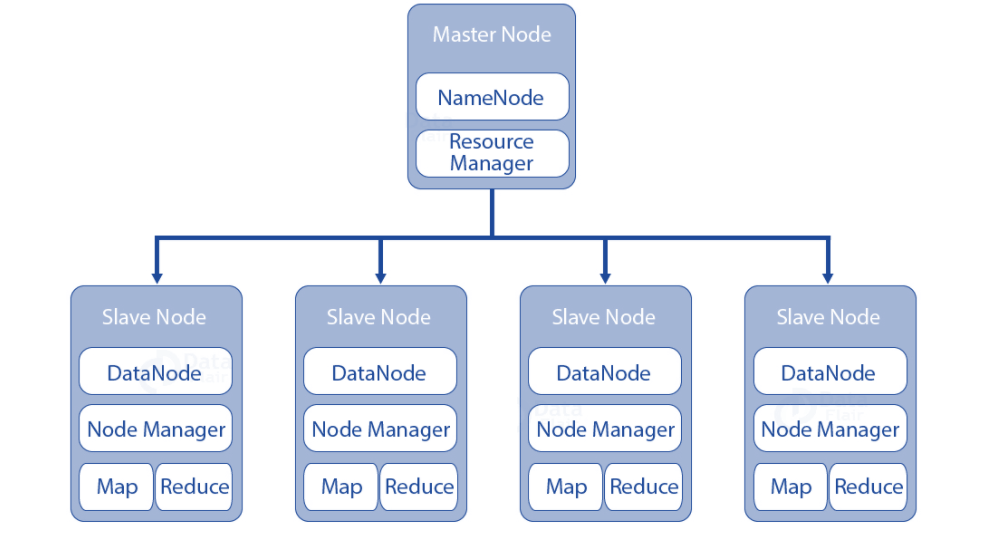
Hadoop 的整体架构如下,由一个主节点和多个从节点构成。主节点负责管理整个集群,存储每个从节点上数据位置之类的元信息。从节点负责存储具体的数据,并进行对应的计算。其中,主节点的 Resource Manager 和从节点 Node Manager 是 YARN 框架的一部分,Node Manager 负责收集每个从节点上 task的资源使用情况,并汇报给 Resource Manager。
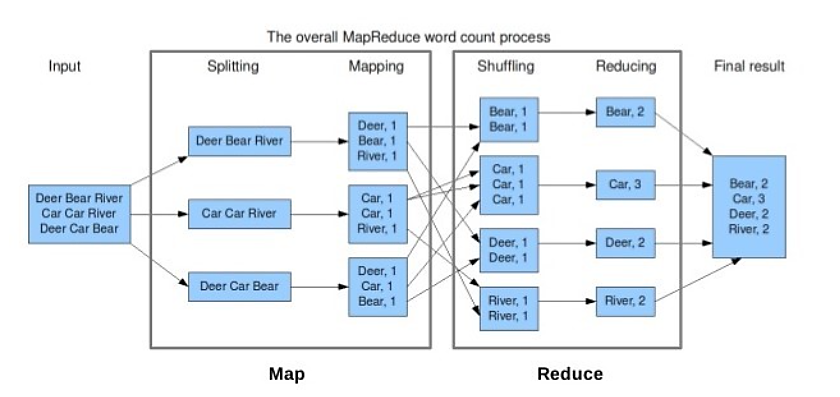
MapReduce的结构如下图,它可以在多个节点并行处理大量的数据,整体的思路是把输入数据拆分成多个块,并行处理,在处理过程中会监控任务执行情况,对于失败任务会进行重试处理。但是 MapReduce 这个计算框架存在一些缺点:
所有中间计算过程的输出数据都会写到存储硬盘,从而影响了执行效率
最初这个框架是为了批量数据设计的,所以不支持实时数据的计算
什么是 spark
Apache Spark 是一个用于大数据处理的统一分析引擎,有内建的模块用于流式处理、SQL、机器学习和图形处理的Spark 可以看作是 MapReduce 的增强版。与 MapReduce 不同,Spark 不会将中间数据存储在磁盘上。
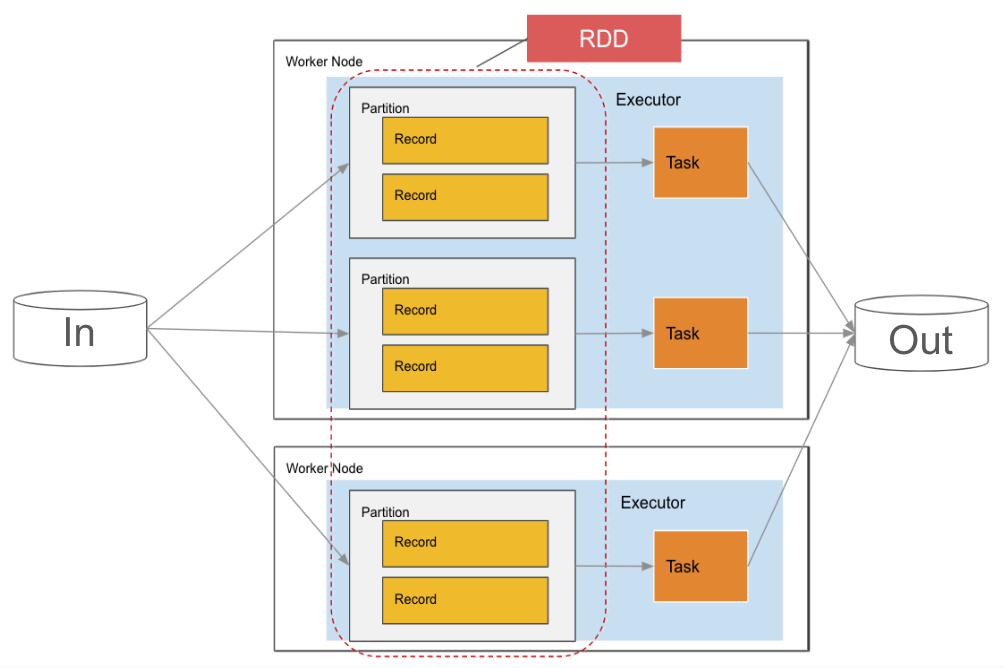
1.RDD(弹性分布式数据集):RDD 是 Spark 的核心抽象。RDD 是分区的集合。其他 API(如DataSet)建立在 RDD 之上。
2.分区是在 SPARK 中处理的最小数据单位。RDD 作为分区分布在每个工作节点上,允许并行处理数据并允许更快的计算。每个分区都由 Executor 中的一个任务处理。分区和任务具有 1:1 的关系。默认情况下,大小为 128MiB,但可以更改。
Spark架构
Spark 遵循类似于 Hadoop 框架的主 / 从(worker)架构,其中 主节点是驱动程序, 从节点是 worker。
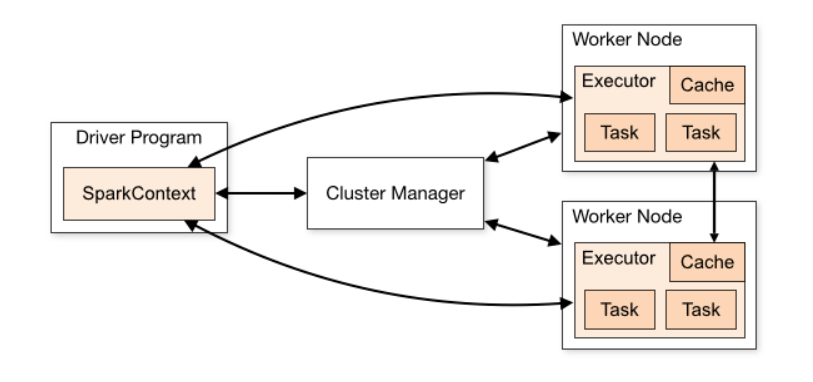 当我们 submit 一个 spark 任务时,主节点会有一个 Driver 程序帮忙我们新建一个 SparkContext。
当我们 submit 一个 spark 任务时,主节点会有一个 Driver 程序帮忙我们新建一个 SparkContext。
Driver 程序会把输入数据拆分成多个块,然后传输到 worker 节点
SparkContext 会将我们的任务拆分成多个 task,然后分发到 worker 节点
Worker 节点负责执行具体 task 任务(每一个 task 任务对应一个分区 partition),并将执行状态返回给 Driver 程序
SparkContext 通过 cluster Manager 来管理整个集群的资源(CPU 和内存)
当一个 Spark 程序提交以后
1.提交 Spark 应用程序代码时,主节点中的驱动程序初始化 SparkContext,并将包含转换和操作的 Spark 代码隐式转换为 DAG(有向无环图)
2.驱动程序执行优化并将 DAG 转换为具有许多任务的物理执行计划,决定将在每个工作节点上执行哪些任务
3.一旦驱动器程序完成了工作分配,它就会与集群管理器协商工作节点的资源。然后,群集管理器代表驱动程序在工作器节点上启动执行程序(excutor)。
4.在执行程序开始执行之前,它们会向驱动程序程序注册自己,以便驱动程序能够全面了解所有执行程序