初探 YOLOv1
YOLO(You Only Look Once),使用CNN方法,一次性检测物体类别 和 位置的算法。是深度学习算法中的一种。突出的优点是端到端检测,速度快。输入为448448的图片,输出为7730的向量(77源自输入切分的Grid,30源自20个类别和2个x,y,w,h,c的加和)。YOLO将物体检测问题看成是回归问题,直接从图片生成图片框坐标和类别。
这里再顺带说一下CNN(卷积神经网络),它是深度学习的一种网络架构,基本结构为:卷积层+池化层+全连接层。其中,卷积层相当于一个过滤器,过滤出图片的某种特征;池化层相当于一个重点提取器,只留下重要的特征;全连接层把上面的网络结构打平,输出分类结果。
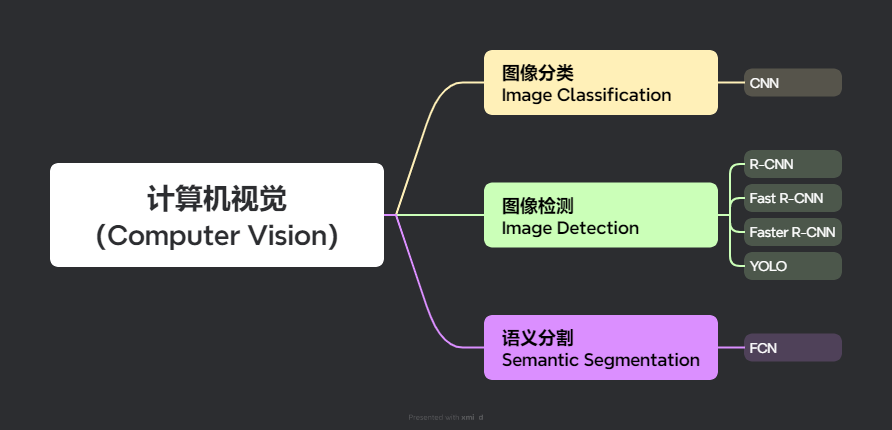
另外,YOLO属于计算机视觉领域的一个分支,所处的位置如下图所示。
推理
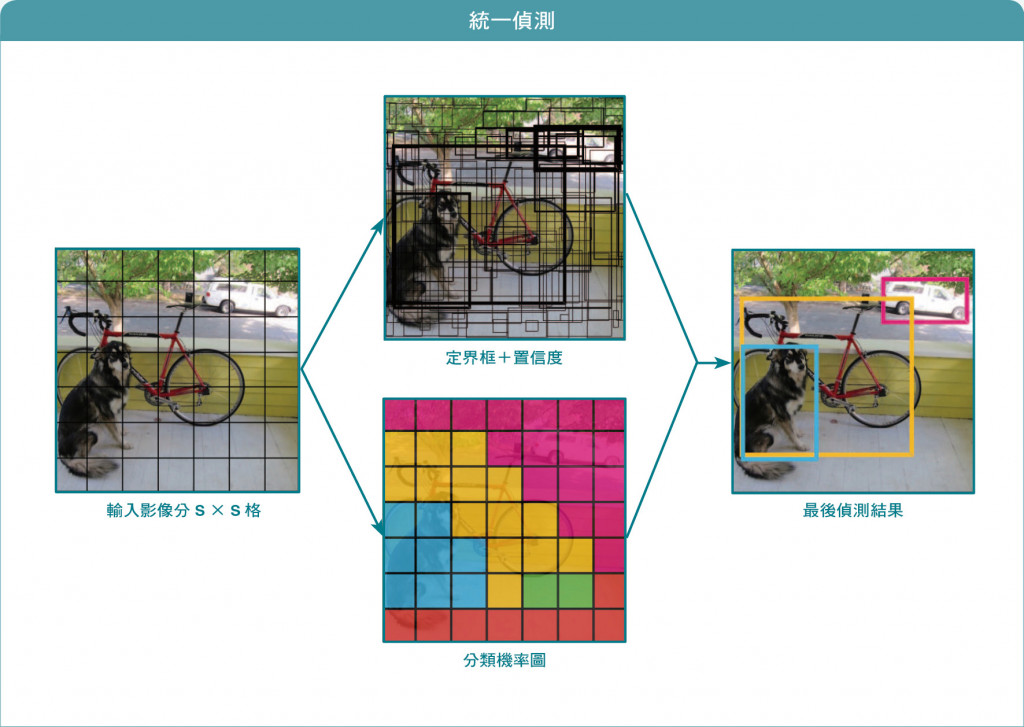
1.将图片切分成S*S个Grid,并分别输出Bounding Boxes+confidence以及Class probability map
2.每个Grid会输出B个Bounding Box以及物件信心值(若不存在物件則Pr(Object)为0)。
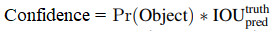
3.Bounding Box预测5个值: x , y , w , h , confidence。
- x , y 为物体在Grid cell中的中心点的位置,0~1之间。
- w , h 为物体边框的宽、长占整体图像的比例,0~1之间。
- confidence: 预测框与真实框之间的IOU
4.每个Grid Cell会预测C类别的可能性(Class Probability map)
训练
Loss Function
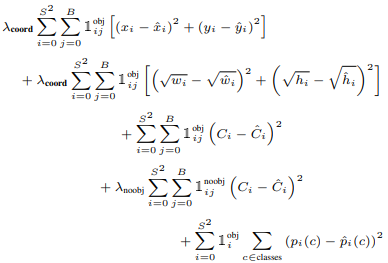
coord是为了加大位置权重的比例,对长、宽求根号是为了提升小物体损失面积的比重,noobj是为了降低其它无效Grid在confidence上面产生的累积效果
超参数
S(grid)=7
B=2(每个grid输出出Bounding Boxes数量为2)
C(Class Probability map)=20 (使用PASCAL VOC数据集,该数据集有20个类别)。
Epochs=135
Batch size=64
Momentum and decay: 0.9 & 0.0005
Learning Rate:
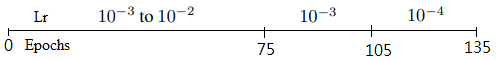
缺点
- 两个不同物体的中心落在同一个Grid的时候,无法检测出这两个物体(因为每一个Grid只能负责检测一个类别的物体)
- 同一类别的物体,如果在训练的时候使用的都是正方形的训练样本,在测试的时候使用长方形或其他形状的图片怎不能很好的识别该类物体