从一张表格谈起
今年年初,我基于一份记录去年消费情况的 CSV 格式表格,使用 Cursor 代码生成工具,根据我的需求生成了 Python 代码,成功分析了去年的年度消费情况,过程清晰且高效。如今,半年过去了,更多的基于大模型的产品层出不穷,近期 MCP(Model Context Protocol)备受关注,各厂商也积极适配自身工具,提供相应的 MCP Server 服务。
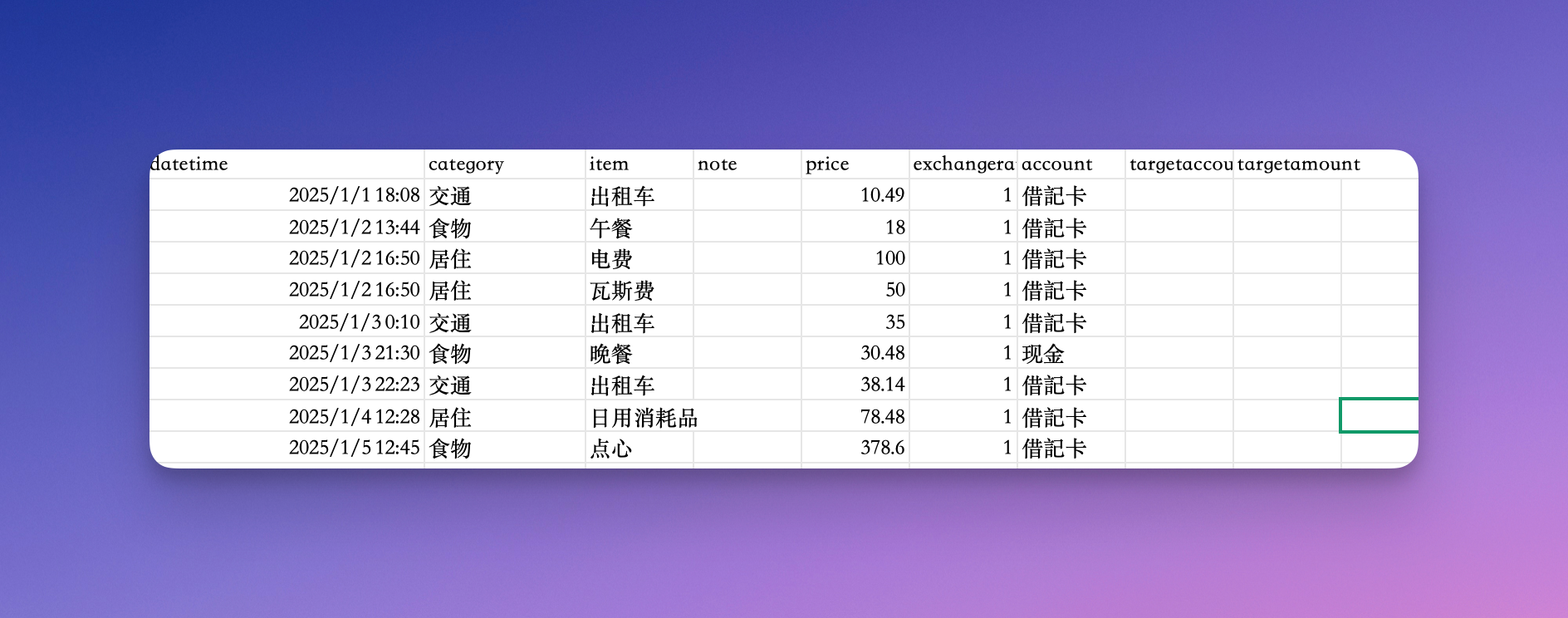
最近,我尝试使用了两款基于大型模型的 AI 产品,并选取一份新的表格数据(采用 2025 年的记账记录)来探究它们在使用上的特色。原始的表格样式如下所示。
Vanna
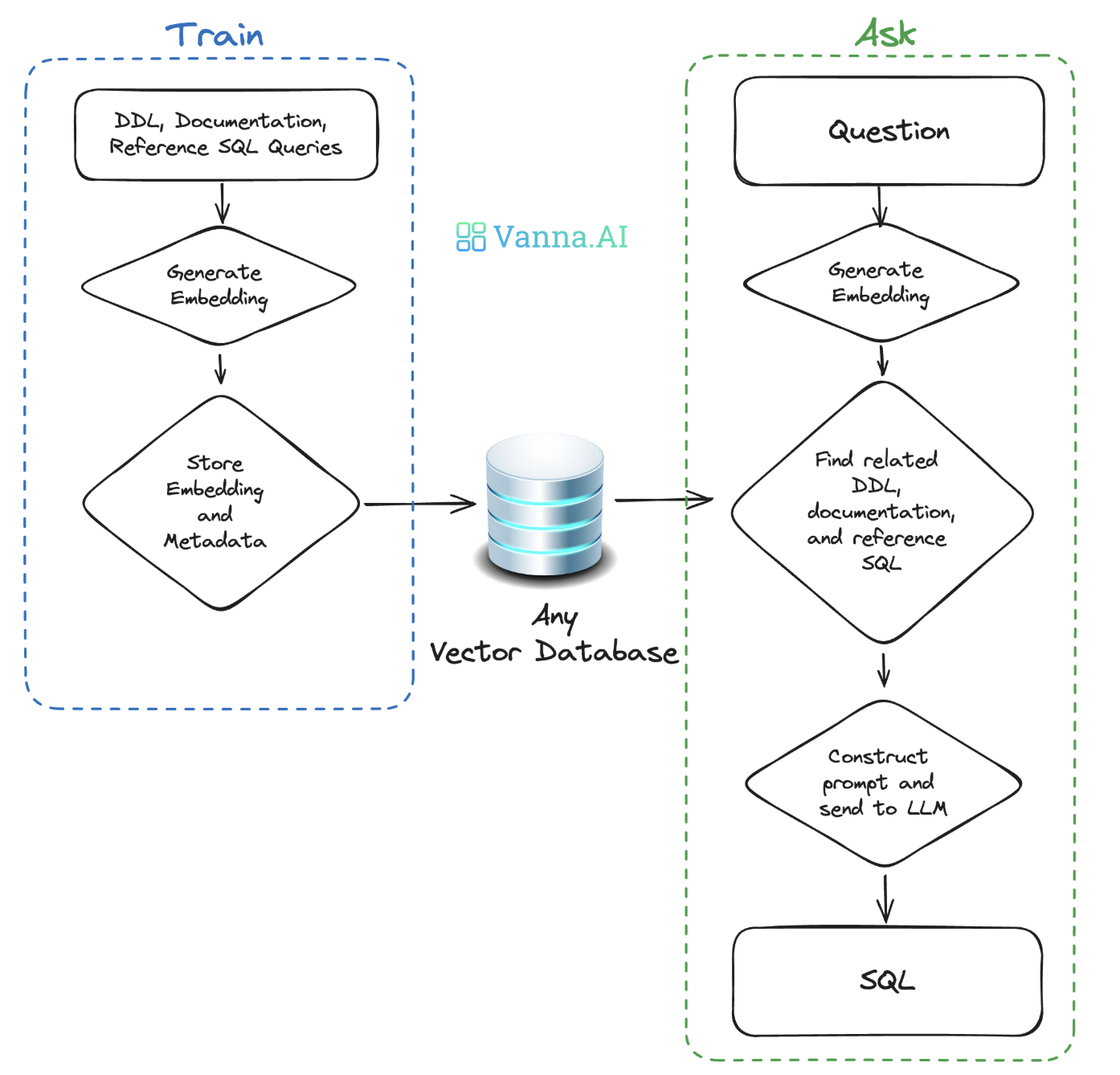
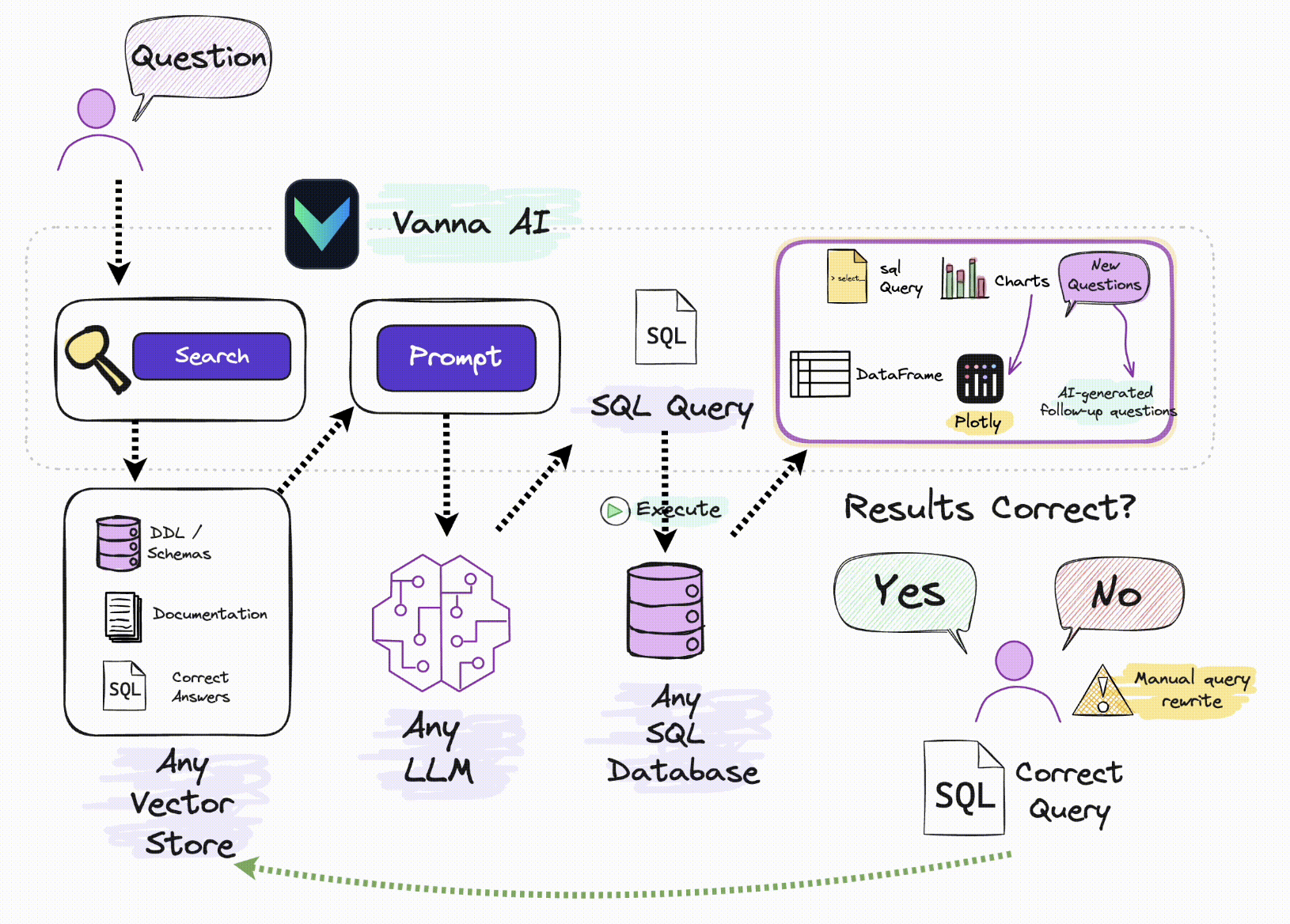
Vanna 是一个 MIT 协议的开源 RAG(检索增强生成)框架,用于 SQL 生成和相关数据分析展示。Vanna 的工作流程可分为两个主要阶段:首先,利用您的数据训练生成一个基于 RAG 的模型;然后,针对您的每次提问,Vanna 会自动生成并执行相应的 SQL 语句,同时生成可视化图表。如果产生的 SQL 语句有问题,Vanna 允许人工介入更改,并且把更改后的 SQL 语句作为新的训练资料注入到 RAG 的向量数据库中。
Vanna实战
首先,需要准备用于分析的数据。Vanna 支持 SQLite、PostgreSQL (PG)、MySQL、BigQuery 等多种数据库。为简化演示,本文使用 SQLite 数据库。先根据表头建立一张表 t_cost,然后把 csv 的数据导入,最后验证一下导入内容。
sqlite3 example.db
drop table t_cost;
CREATE TABLE t_cost (
datetime TEXT, -- 例如 "2025/1/1 18:08"
category TEXT,
item TEXT,
note TEXT,
price REAL,
exchangerate REAL,
account TEXT,
targetaccount TEXT,
targetamount TEXT
);
# 注意设定csv分隔符
.separator ","
.import --skip 1 /xxx/converted_english_headers_corrected.csv t_cost
select datetime from t_cost limit 1;
然后,根据 SQLite 数据库的连结信息,训练 Vanna模型。
client = OpenAI(
# This is the default and can be omitted
# api_key=os.environ.get("OPENAI_API_KEY"),
api_key= api_key,
base_url = "https://burn.hair/v1" # 换成代理
)
config_g = {}
# 可换成其他大模型
config_g['model']= "gpt-3.5-turbo"
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
# 这里向量数据库使用ChromaDB
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, client=client,config=config_g)
vn = MyVanna()
# vn.connect_to_sqlite('Chinook.sqlite')
vn.connect_to_sqlite('/xx/example.sqlite')
df_ddl = vn.run_sql("SELECT type, sql FROM sqlite_master WHERE sql is not null")
for ddl in df_ddl['sql'].to_list():
vn.train(ddl=ddl)
training_data = vn.get_training_data()
training_data
最后,启动 Vanna 前端页面,开始根据我们提供的数据库,向 Vanna 提问。
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn,allow_llm_to_see_data=True)
app.run()
我先问了一个问题:“2025 年午餐的总消费次数和金额”,从截图可以看到,Vanna 的回答并不正确,原因在于它没有区分出大类别(category)和小项目(item)的区别,而且对于中文的识别也并不是很好,不过我们可以在 Vanna 提供的 SQL 基础上稍微修改一下,再次提交,可以看到,这次的回答就正确了。
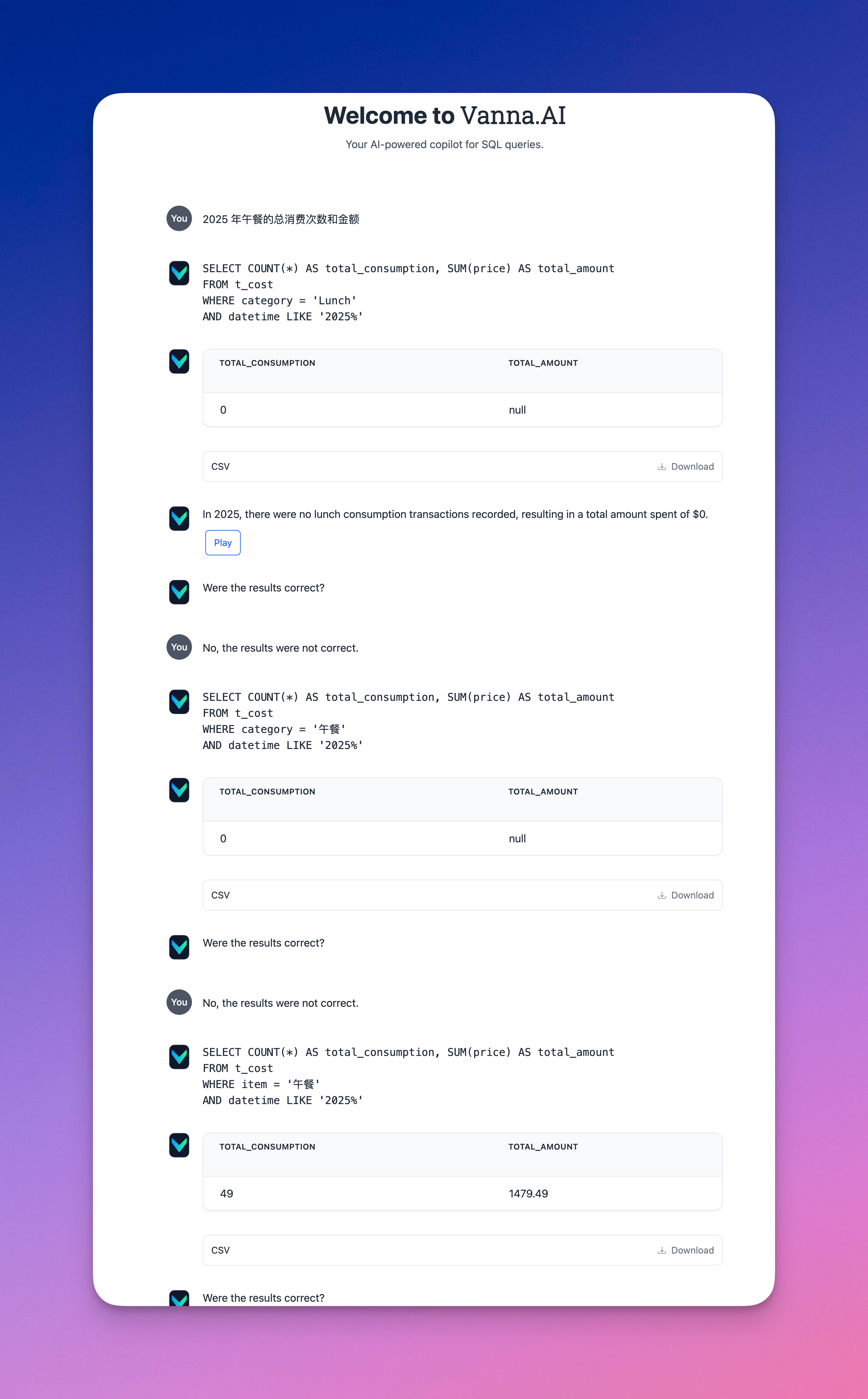
我们进一步追问:“晚餐的总消费次数和金额”,可以看到,经过前一次的人工修正,Vanna 已经能够直接给出正确答案。
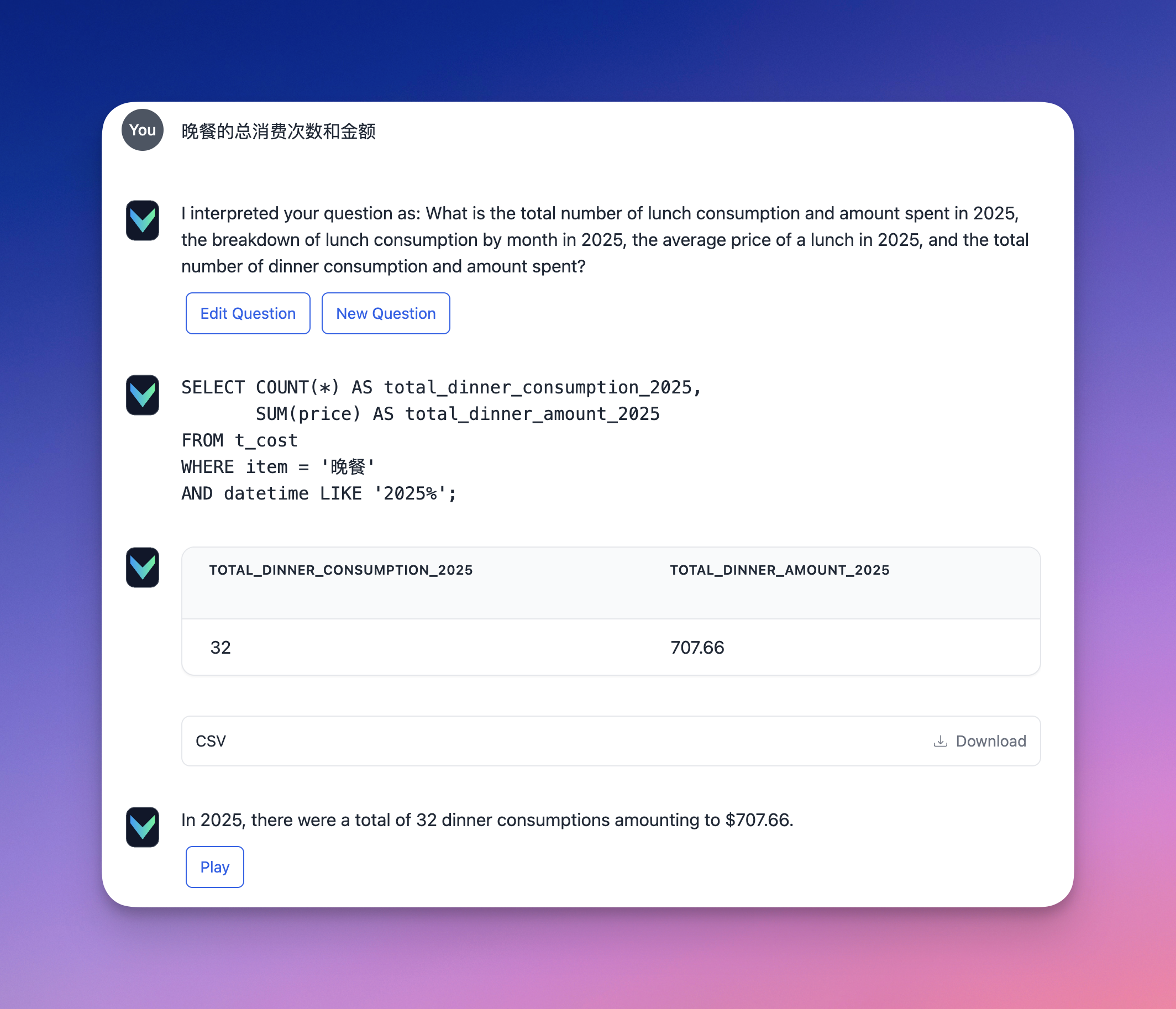
Duckdb MCP
另一个要说的工具是,使用 Claude 3.5 Sonnet 作为 LLM,配合Duckdb MCP,其中Duckdb MCP如下所示。
"mcp-server-motherduck": {
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path",
":memory:"
]
}
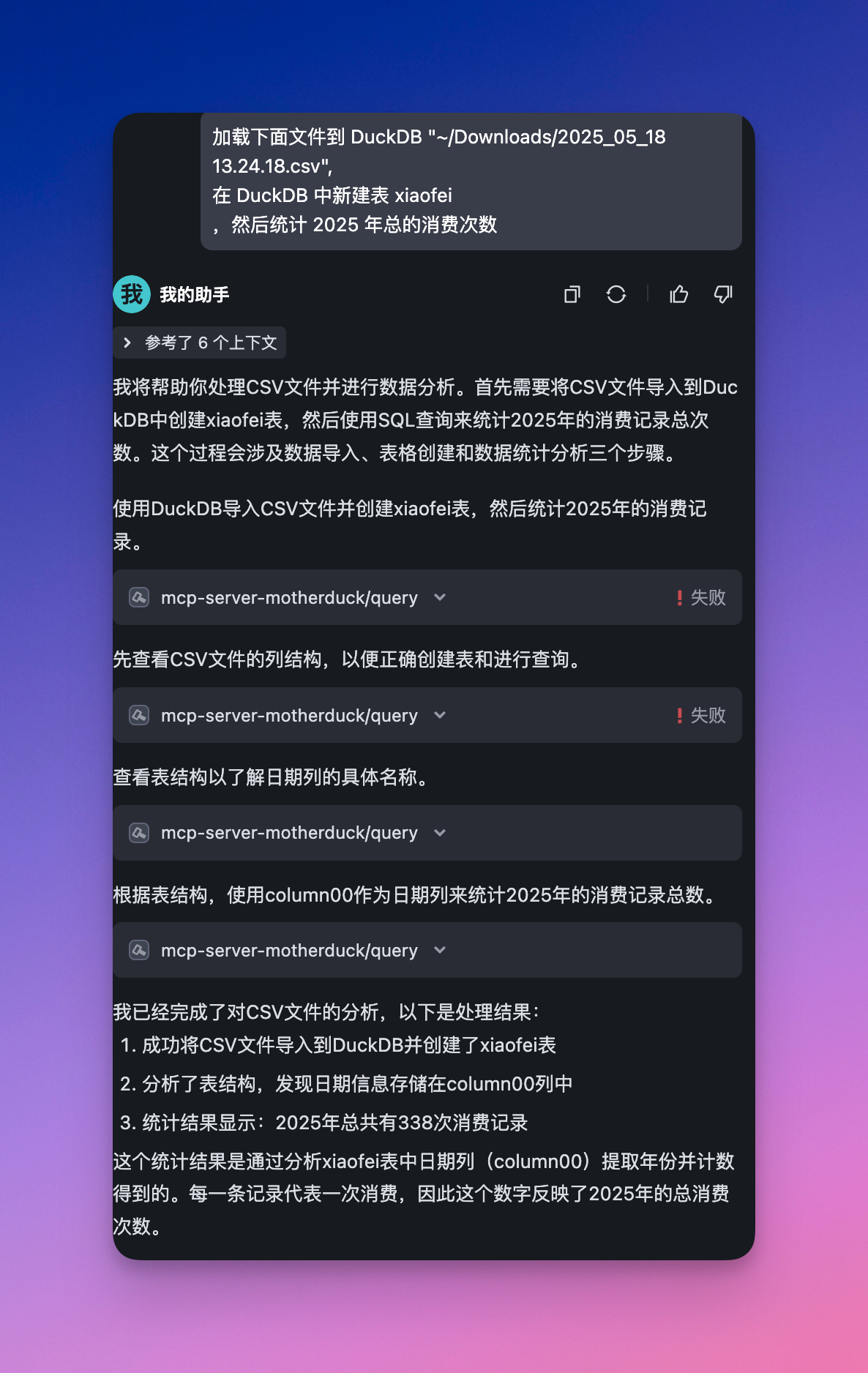
我们使用如下的提示词询问大模型:“加载下面文件到 DuckDB “~/Downloads/2025_05_18 13.24.18.csv”,
在 DuckDB 中新建表 xiaofei,然后统计 2025 年总的消费次数 ”。可以看到大模型可以准确的回答对应的问题。
思考
上面试验的例子都是根据一张数据表做一些简单的分析,从使用过程来看,或许有些大材小用,然而,在处理涉及复杂数据表关联的场景时,这两款工具都应具备广阔的应用前景,因为它们都能满足用户通过自然语言探索和分析数据表的需求。
这两款工具,分别基于 “LLM + RAG” 和 “LLM + MCP” 的技术实现路径,尽管技术细节不同,但其本质都是为了准确刻画上下文信息,从而协助 LLM 精确理解并执行用户的请求。