AI 新手村:CLIP
2021 年 OpenAI 在推出 1750 亿参数的 GPT-3 模型的时候,也推出了 120 亿参数的 DALL·E模型和几亿参数的 CLIP 模型,这两个模型都是多模态模型(不仅可以处理文本还可以处理图片)。
然而,这两者的类型和应用场景有所不同。DALL·E模型是生成式模型,它学习数据的分布并能生成新的数据样本,与 GPT 系列异曲同工。而 CLIP 模型则属于判别式模型,它旨在学习数据之间的区分边界,主要用于分类和判断,但不能生成新样本。具体来说,DALL·E模型的核心功能是根据文本生成图像,常见于封面设计等场景;CLIP 模型则主要用于计算文本与图像的相似度,广泛应用于图像搜索和文案推荐。
CLIP
CLIP 是一种多模态模型,它通过对比学习来对齐文本和图像,也就是把文本和图像映射到同一个空间中,比如提到“狗”这个文本的时候,通过 embedding 对应高维空间的一个点,而提到一个包含有狗的图像的时候,通过 embedding 也会对应同一个空间的点,CLIP 的目标是让这两个对应的点尽可能接近。
CLIP的训练
CLIP 模型由图像编码器(通常是 ViT 或 ResNet)和文本编码器(Transformer)组成,在训练这个模型的时候,图像编码器负责把一张图片映射到空间中的某一点,文本编码器负责把一段文字映射到空间中的某一点。每次训练拿出 n 张图片和对应的文字,n 张图片丢给图像编码器产出 In,n 段文字丢给文本编码器产出 Tn,我们定义损失函数为对应的(In,Tn)要越像越好,也就是内积相乘越大越好,对应的就是图中蓝色部分。而其余部分则希望它们的相似度尽可能低,通过内积值越接近 0 来表示(图中灰色部分)。
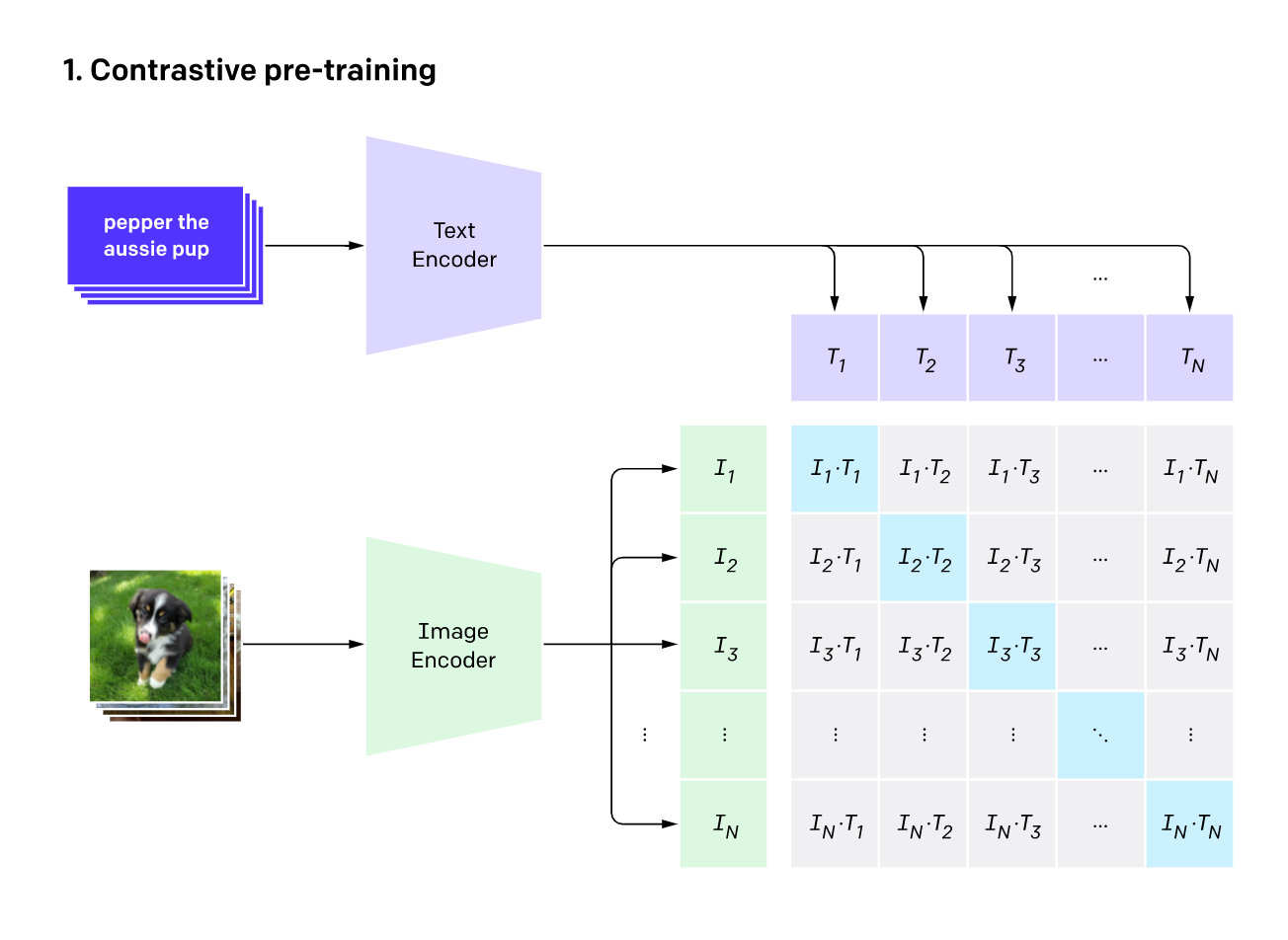
CLIP的推理
在使用 CLIP 模型的时候,我们给出几段文字和一张图片,CLIP 模型会计算图像嵌入与每一段文本嵌入在共享空间中的相似度(内积值),并输出与图像最接近的文本(即内积值最大的文本)。
同理,我们也可以给出多张图片和一段文字描述,从而得到与该文字描述最接近的图片。例如,知名的图片网站 Unsplash 就是利用 CLIP 模型实现了其全站图片检索功能。
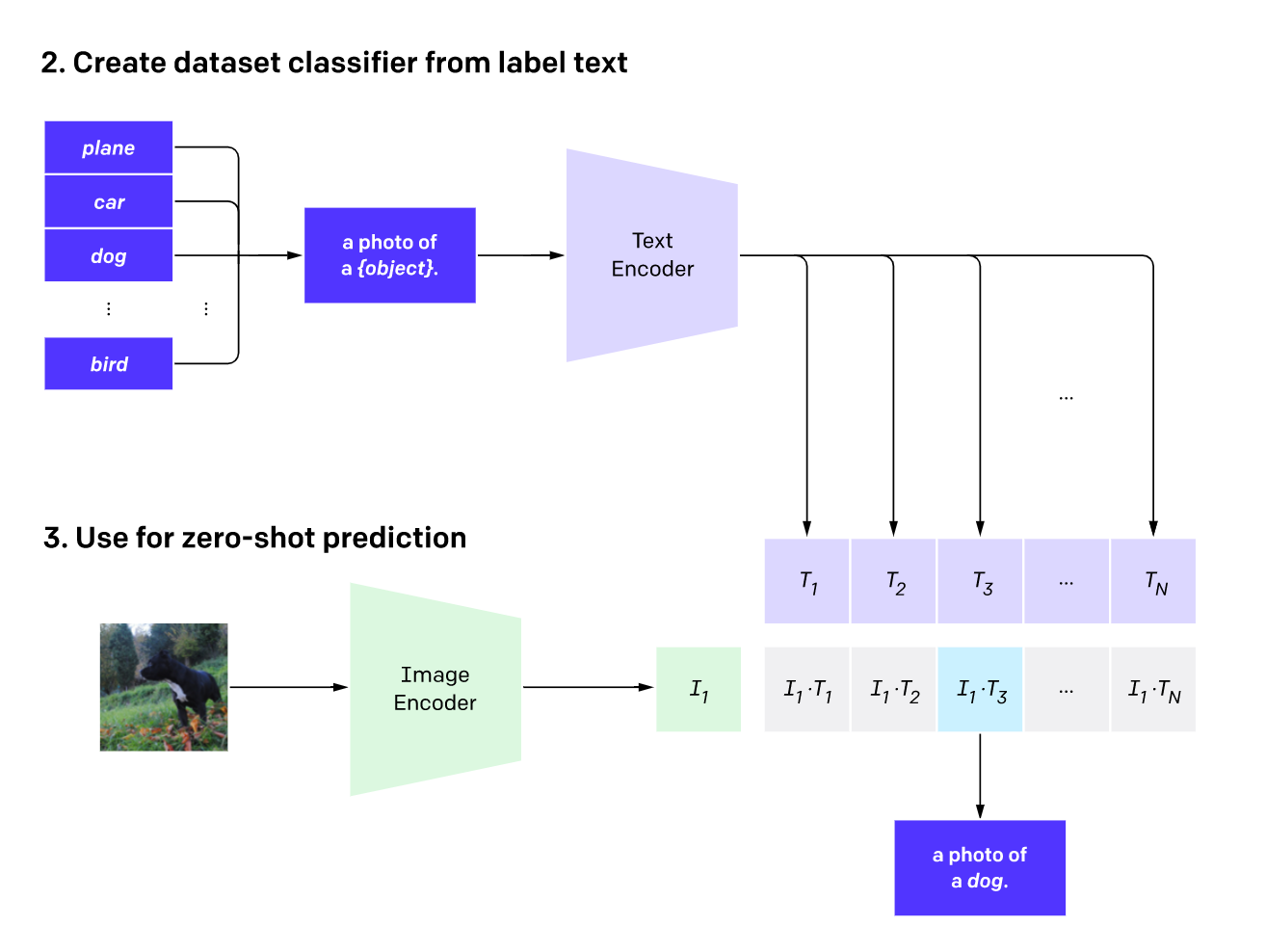
CLIP的优缺点
CLIP 模型以其快速的计算速度和对不同类型图片内容出色的泛化识别能力而著称。然而,它的主要缺点在于对图像中细节的识别能力相对较弱。例如,在以下以图搜图的场景中,将一张正在缫丝的图片传递给不同模型时,CLIP 模型可能仅能捕捉到这是一种 “手工艺活动”,而无法识别出具体的精细缫丝过程,这与一些更专业的模型DINO-v2 和 BLIP2有所不同。

CLIP 实战演示
我们将选择一个本地图片文件夹,遍历目录下所有图片并通过 CLIP 建立 Embedding。然后,通过一段文本或一张图片进行检索查询,找出最相似的前 5 张图片。
from sentence_transformers import SentenceTransformer
import random
import glob,os
from PIL import Image
import matplotlib.pyplot as plt
#图片目录
image_folder = 'xxx/xx'
# 使用CLIP模型构建特征
def generate_clip_embeddings(images_path, model):
image_paths = glob.glob(os.path.join(images_path, '**/*.jpg'), recursive=True)
embeddings = []
for img_path in image_paths:
image = Image.open(img_path)
embedding = model.encode(image)
embeddings.append(embedding)
return embeddings, image_paths
model = SentenceTransformer('clip-ViT-B-32')
embeddings, image_paths = generate_clip_embeddings(image_folder, model)
import faiss
import numpy as np
# FAISS 构建索引
features = np.array(embeddings).astype(np.float32)
faiss.normalize_L2(features)
vector_dim = features.shape[1]
index = faiss.IndexFlatIP(vector_dim)
index.add(features)
# 图片查询:选一张图(或上传图)再计算 embedding 作为查询向量
# query_image = Image.open('xxxx/feiji.jpeg')
# query_vector = model.encode(query_image)
# query_vector = np.array(query_vector).reshape(1, -1).astype(np.float32)
# faiss.normalize_L2(query_vector)
# 文本查询
query_text = "一辆自行车"
query_vector = model.encode(query_text) # 使用同一个模型对文本编码
query_vector = np.array(query_vector).reshape(1, -1).astype(np.float32)
faiss.normalize_L2(query_vector)
# 搜索最相似的图片
top_k = 5
distances, ann = index.search(query_vector, k=top_k)
# 显示搜索结果
for i, idx in enumerate(ann[0]):
print(f"Top {i+1} match: {image_paths[idx]} (Score: {distances[0][i]:.4f})")